
La mise en valeur du patrimoine culturel passe aujourd’hui entre autres par le numérique. Dans cette démarche a été lancé le projet de valorisation de photographies d’archéologie classique conservées par l’Université de Strasbourg.
En intégrant ces images dans la médiathèque libre Wikimedia Commons, l’objectif est double : offrir un accès à ces ressources sur l’encyclopédie Wikipédia et faire le lien vers la bibliothèque Numistral et valoriser les métadonnées associées en présentant des fiches d’une grande richesse.
Numistral et fond d’archéologie classique
Numistral est « la bibliothèque numérique patrimoniale du site universitaire alsacien et de ses partenaires ».
Ouvert en octobre 2013 comme bibliothèque numérique patrimoniale de la Bibliothèque nationale et universitaire de Strasbourg (Bnu), il a évolué pour devenir, dans le cadre du contrat de site alsacien 2013-2017, le portail d’accès aux collections documentaires numérisées des établissements d’enseignement supérieur et de recherche alsaciens (Bnu, Université de Haute Alsace et Université de Strasbourg), ainsi que de leurs partenaires. Depuis 2022, il s’élargit à de nouveaux partenaires relevant de collectivités territoriales, parmi lesquels la Bibliothèque municipale classée de Mulhouse.
La collection de photographies anciennes d’archéologie classique de l’Université de Strasbourg comprend plus de 12 500 tirages papiers dont 1800 environ proviennent de la collection personnelle du fondateur et premier directeur de l’Institut d’Archéologie classique (Kunstarchäologisches Institut) Adolf Michaelis (1835-1910) qui fut acquise par l’université au lendemain de sa mort.
– Extrait de la page « Histoire » du site internet de Numistral.
Impulsion
L’initiative de valorisation a été prise par le service de la bibliothèque numérique patrimoniale de Strasbourg. L’idée est d’intégrer ces photographies – qui sont maintenant dans le domaine public – sur Wikimedia Commons, afin de les rendre accessibles à un large public et de pouvoir les ajouter sur Wikipédia.
Le projet a nécessité un choix méthodologique afin de le rendre viable dans le temps. L’outil retenu pour l’importation des fichiers en masse est Pattypan, une application open source conçue pour faciliter le transfert d’images vers Wikimedia Commons.
Une fois les fichiers récupérés auprès du service, il a fallu compléter et structurer les métadonnées en amont de l’importation, sous forme de tableurs. Pour garantir une qualité optimale, l’ensemble du processus s’est déroulé par vagues successives, permettant des ajustements en cours de route.
Concrètement ?
Concrètement, les étapes semblent simples. Il suffit de générer avec Pattypan les tables d’import à partir des fichiers. Ensuite, il faut compléter toutes les colonnes de métadonnées : auteur·e ; date ; technique ; catégories Commons…
Les catégories Commons
Oui, il faut également compléter les catégories Commons pour que les fichiers ne soient pas perdus dans la médiathèque. Le fameux F du principe FAIR : findable. Pour celles et ceux qui ne connaissent pas Wikimedia Commons, disons que les catégories sont comme des poupées russes. Une catégorie peut elle-même être rangée dans une autre, et ainsi de suite, pour former des arborescences de rangement, à l’instar de dossiers sur un ordinateur.
Prenons un exemple, avec cette image d’un forum romain.

Cette image est placée dans deux catégories, « Rome dans le fond Adolf Michaelis sur Numistral » et « Historical images of Tabularium (Rome) ». Mais ces catégories sont placées dans d’autres catégories. On se retrouve rapidement avec un arbre de ce type :
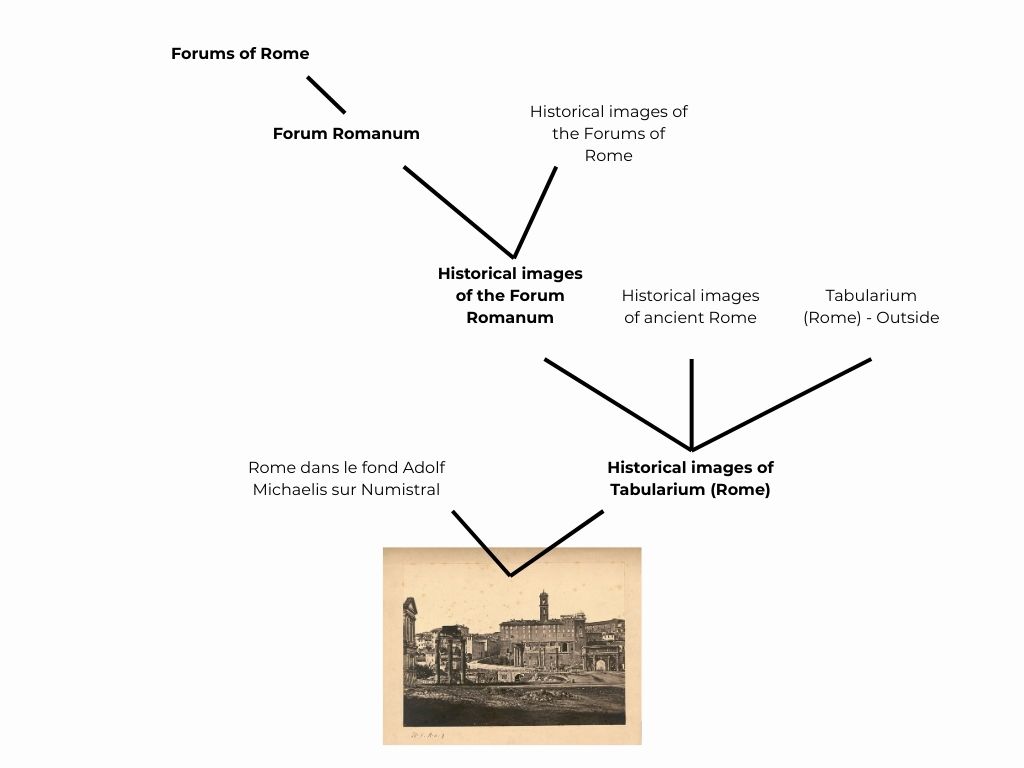
Concentrons-nous rapidement sur les catégories en gras pour constater que, pour chaque branche, c’est un enchainement de dizaines, voire de centaines de catégories. Voici le schéma d’une branche de catégories Commons, allant de « Works of art » à « Historical images of Tabularium (Rome) ».
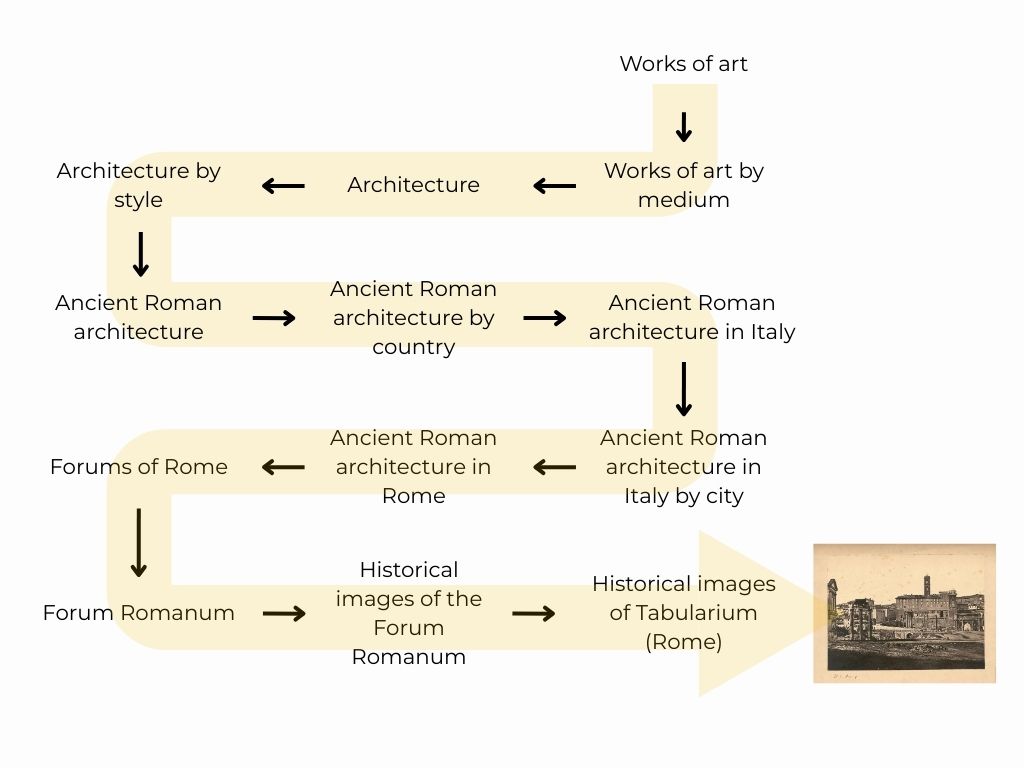
La règle pour rendre les fichiers trouvables est d’ajouter toujours la catégorie la plus précise à l’image. En effet, on ne va pas catégoriser cette image avec « Architecture », concept qui est bien trop large.
Il apparaît donc la première difficulté de ce projet : trouver les catégories optimales pour les 500 images concernées, sans passer manuellement sur chacune d’entre elles.
Complétion des catégories
Ainsi, j’ai utilisé les métadonnées existantes pour en extraire des “sujets”. Pour cette image par exemple, voici un extrait des données dont je disposais :
| Titre en français | Sujet | Subject |
| Forum Romain : vue générale depuis le Palatin | Rome (Italie) — Foro romano | Roman Forum (Rome, Italy) |
L’idée était alors d’utiliser le logiciel OpenRefine pour réconcilier les sujets avec Wikidata. Ici, « Foro romano » est réconcilié. Et depuis Wikidata, il est possible de récupérer les catégories Wikimedia Commons correspondantes.
Il faut tout de même garder à l’esprit que cette technique n’est pas infaillible et que la précision peut être inexacte. Ainsi, un passage manuel sera probablement nécessaire, mais ce travail peut être laissé à la communauté bénévole Wikimedia Commons.
Import des images
Les tableaux étant maintenant complets, l’import peut commencer ! Pour cela, rien de plus simple, il suffit de donner à Pattypan les chemins d’accès aux fichiers et le tableau, et il s’occupe de tout.
Une fois les premières images importées, une nouvelle réunion a eu lieu pour faire le point. Une chose était manquante : les liens directs vers les images dans la bibliothèque numérique Numistral. Un autre défi, puisque les liens ne font aucune correspondance avec le numéro d’inventaire de l’image.
Pour rester sur le même exemple, notre image de forum romain est accessible au lien http://cdm21057.contentdm.oclc.org/cdm/ref/collection/coll4/id/493. La structure du lien est toujours la même, mais le nombre de fin, ici « 493 », change et ne peut pas être deviné à partir des métadonnées. Un vrai casse-tête !
Récupération des liens et alignement
Alors pour résoudre ce problème, j’ai tenté un petit coup de magie. Après avoir listé les liens « probables », c’est à dire tous les liens avec des numéros qui se suivent, j’ai récupéré les pages web associées, en faisant un moissonnage informatique à l’aide de OpenRefine.
Une fois tous les codes sources récupérés depuis les liens, j’ai isolé la partie qui comporte le numéro d’inventaire. Dans le code, on retrouve le numéro d’inventaire (en gras ci-dessous) comme ceci :
{\"key\":\"titlea\",\"label\":\"Num\u00E9ros d'inventaire\",\"controlledVocab\":false,\"searchable\":true,\"value\":\"It.I.A.a.3\",\"controlledVocabList\":null}Avec un coup de baguette magique (toujours grâce à OpenRefine) pour isoler les numéros, il a ensuite été possible de mettre en parallèle les liens directs avec les numéros d’inventaire.
Comme on aime le dire dans la communauté wikimédienne : « OpenRefine is magic » !

Ne reste ensuite plus qu’à ajouter ces liens sur les fiches déjà importées grâce à Pattypan et les intégrer aux imports suivants.
Finalité et accueil de la communauté
Au final, ce sont plus de 500 photographies d’archéologie classique qui ont été importées sur Wikimedia Commons, pour un projet ayant duré plus de 6 mois, entre toutes les réunions, le traitement des données et la vérification manuelle des liens directs.
La communauté wikimédienne a été informée par une publication sur Le Bistro de Wikipédia le 10 mars 2025, les invitant à s’approprier le fond pour illustrer l’encyclopédie.
L’accueil de ce projet par les bénévoles fait du bien !
[…] Mickaël Schauli a procédé à l’import du fond Numistral durant sa résidence à l’URFIST de Strasbourg. En savoir plus. […]